Come risolvere gli errori di crawling negli strumenti per i Webmaster? | Weboptim
Negli ultimi anni sono cambiate molte cose negli Strumenti per i Webmaster. Le sezioni Statistiche di ricerca e Link al vostro sito sono le due migliori innovazioni finora.
Sezione errori di mappatura
Gli strumenti per i webmaster possono essere suddivisi in due parti principali: errori del sito web ed errori dell'URL.
La classificazione degli errori in questi due gruppi è molto utile, poiché esiste una netta differenza tra gli errori a livello di sito web e di sottopagina.
- Gli errori a livello di sito web sono più gravi, in quanto possono rovinare l'usabilità dell'intero sito.
- Gli errori URL riguardano una sottopagina e sono quindi problemi meno urgenti.
La home page di WMT offre una rapida panoramica del nostro sito, con 3 importanti strumenti: Errori di crawling, Statistiche di ricerca, Mappe del sito.
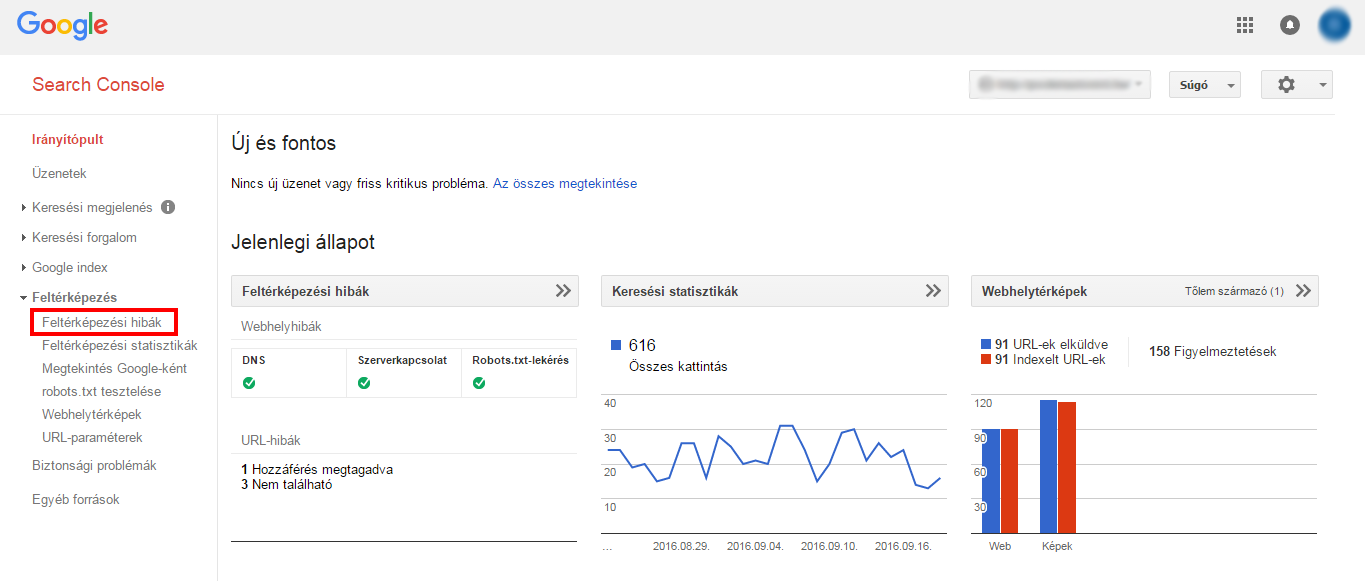
Gli errori di mappatura sono facilmente accessibili nell'interfaccia degli Strumenti per i Webmaster.
1. Errori del sito web
La sezione Errori del sito web mostra gli errori dell'intero sito. Questi sono gli errori di livello più alto e non dovrebbero mai essere ignorati. La pagina mostra i dati degli ultimi 90 giorni.
Se c'è stata un'attività negli ultimi 90 giorni, la si può vedere qui:
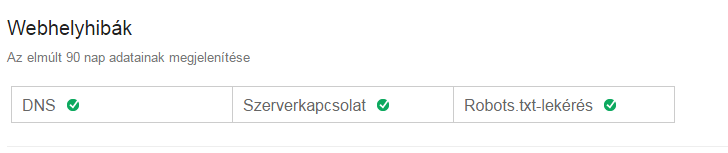
Se il sito è stato privo di errori in 100% negli ultimi 90 giorni, allora questo:

Con quale frequenza controlliamo gli errori del sito?
Idealmente, dovremmo controllare ogni giorno per vedere se c'è un problema. È un lavoro molto monotono perché la maggior parte dei giorni non cambia nulla, ma cosa succede se non controlliamo e ci sfuggono errori critici?
Verificare la presenza di errori precedenti almeno ogni 90 giorni! Questa sezione è fondamentale ed è necessario che il 100% sia privo di errori ogni giorno.
A, errori del DNA
Che cosa significa?
Gli errori del DNA sono importanti. Il primo e più importante, perché se Googlebot trova un errore DNS, significa che Google non può connettersi al dominio attraverso il server DNS.
Perché è importante?
Se viene rilevato un grave problema di DNA, è necessario intervenire immediatamente. Il DNA è molto importante perché è il primo passo per accedere al sito. È necessario intervenire con decisione se si riscontra un errore DNS.
Come risolvere il problema?
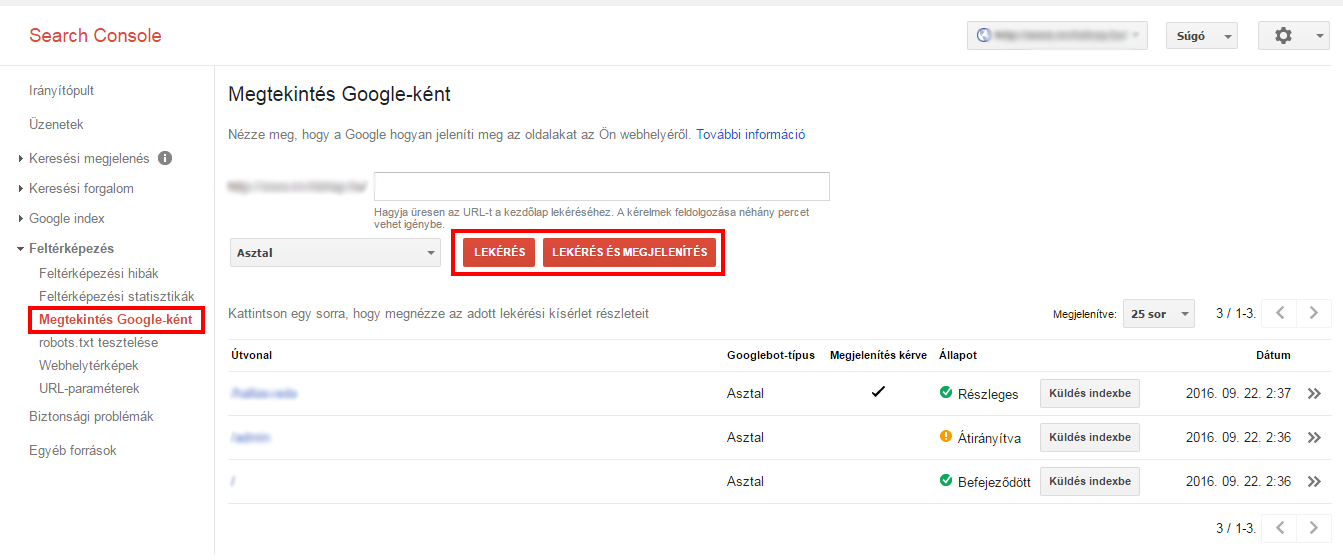
1. In primo luogo, Google raccomanda un Visualizza come Google dove è possibile vedere come Googlebot sta mappando il vostro sito.
2. Se si desidera controllare solo lo stato del DNA, utilizzare il pulsante Recuperato da selezionare l'opzione. A Richiesta e visualizzazione è un processo leggermente più lento, ma è utile quando si vuole confrontare il modo in cui Google vede la propria pagina in relazione agli utenti.
3. Controllare il proprio provider DNS. Se Google non è in grado di recuperare la pagina, sono necessari altri passaggi.
4. Assicurarsi che il server mostri i codici di errore 404 e 500. Invece di mostrare una connessione fallita, dovrebbe mostrare 404 (non trovato) o 500 (errore del server).
B, Errori del server
Che cosa significa?
Un errore del server di solito significa che il tempo di risposta del server è troppo lungo e la richiesta ha superato il tempo consentito. Quando Googlebot tenta di effettuare il crawling della pagina, attende solo un certo tempo di caricamento prima di fermarsi. Se il tempo di caricamento è troppo lungo, si ferma.
Gli errori del server sono diversi dagli errori DNS. DNS significa che Googlebot non può vedere l'URL a causa di un problema DNS, mentre gli errori del server significano che Google può connettersi alla pagina ma non può caricarla a causa di un errore del server.
Gli errori del server possono verificarsi quando il nostro sito riceve troppi visitatori e il server non è in grado di gestire l'aumento del traffico.
Perché è importante?
Proprio come gli errori DNS, anche gli errori del server vengono risolti in fretta. Si tratta di un errore di base che ha un effetto negativo sull'intero sito web.
Come risolvere il problema?
Innanzitutto, assicuratevi che Googlebot possa connettersi al vostro DNS.
Se il sito web funziona bene e si verifica questo errore, potrebbe significare che in passato si sono verificati errori del server. Anche se l'errore è già stato risolto, è necessario apportare delle modifiche per evitare che si ripeta.
Guida ufficiale di Google alla risoluzione degli errori del server:
Utilizzate lo strumento Visualizza come Google per vedere come Googlebot effettua il crawling della pagina. Se si interroga una pagina e Google visualizza la pagina principale senza problemi, si può presumere che Google sia in grado di accedere alla pagina correttamente.
Gli errori del server possono avere diverse cause/tipologie: timeout, intestazioni troncate, recupero della connessione, connessione negata, connessione fallita, timeout della connessione, nessuna risposta. Per risolvere ciascun errore, utilizzare la Guida di Webmaster Tools: https://support.google.com/webmasters/answer/35120?hl=en
C, Richiesta di robots.txt non andata a buon fine
Una richiesta di robots.txt non andata a buon fine significa che Googlebot non è in grado di recuperare il file robots.txt per il sito web, che si trova all'URL [yourdomain.com]/robots.txt.
Che cosa significa?
Una delle cose più sorprendenti del file robots.txt è che è necessario solo se si desidera che Google non mappi alcune pagine (ad esempio, le pagine degli amministratori).
Perché è importante?
È una domanda molto importante. Per i siti web più piccoli e statici, con poche modifiche o nuove pagine, non è così importante. Ma ovviamente vale la pena di migliorarla.
Ma se il vostro sito cambia frequentemente i contenuti, è un compito immediato risolvere il problema. Se Googlebot non riesce a scaricare il file robots.txt, non può effettuare il crawling della pagina e quindi le nuove pagine o le modifiche non saranno indicizzate.
Come risolvere il problema?
Assicurarsi che il file robots.txt sia configurato correttamente.
Controllare due volte le pagine che non si desidera siano sottoposte a crawling.
Controllate tre volte la riga più importante "disallow:/" e assicurarsi che non esista, a meno che per qualche motivo non si voglia che il sito web appaia nei risultati di ricerca.
Se il file sembra buono, ma mostra comunque degli errori, usate il verificatore di codice HTML per vedere se restituisce 200 o 400 codici HTML.
È meglio non avere alcun file robots.txt piuttosto che averne uno non impostato correttamente. In caso contrario, Google effettuerà il crawling come di consueto. Se invece esiste ed è danneggiato, Google interromperà il crawling fino a quando il file non verrà corretto.
2. Errori URL
Gli errori URL sono molto diversi dagli errori del sito web perché riguardano solo le singole pagine di un sito web, non l'intero sito.
Webmaster Tools mostra i principali errori URL per categoria: desktop, smartphone. Per i siti più grandi questo elenco probabilmente non è sufficiente per identificare tutti gli errori, ma per la maggior parte dei siti può identificare tutti i problemi.
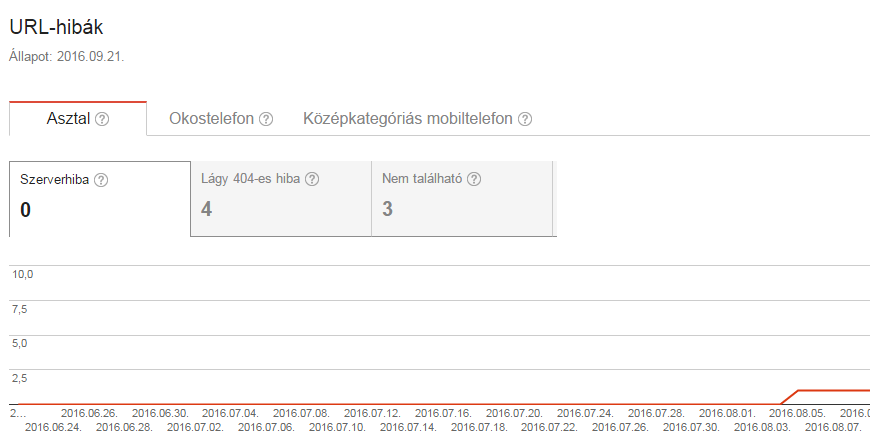
Vediamo troppi errori? Segnateli come corretti!
Molti proprietari di siti web sono inorriditi dal numero di errori URL. La cosa più importante da ricordare è
- a, Google mostra solo gli errori più importanti
- b, alcuni di questi sono già stati risolti
Se sono state apportate modifiche drastiche al sito per correggere gli errori o se si ritiene che molti errori URL non esistano più, selezionare Segna come risolto e tornare a controllare tra qualche giorno.
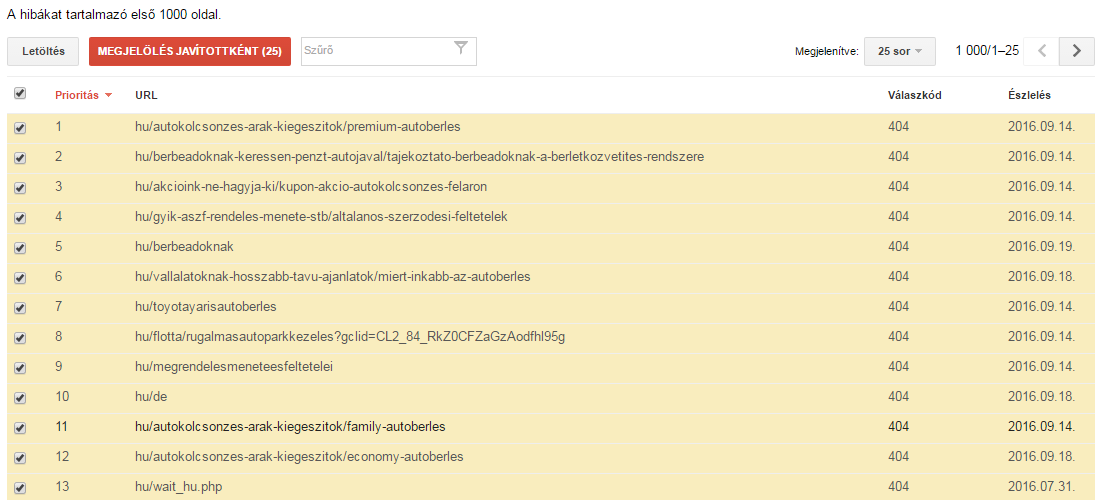
In questo modo, gli errori scompariranno dalla tabella e, se non sono stati corretti, Google li visualizzerà di nuovo al successivo crawling. Se gli errori sono stati effettivamente corretti, non riappariranno. Se gli errori sono ancora presenti, sapremo che stanno influenzando il nostro sito.
A, morbido 404
Un errore soft 404 significa che la sottopagina restituisce un codice di risposta 200 (ok) anziché 404 (non trovato).
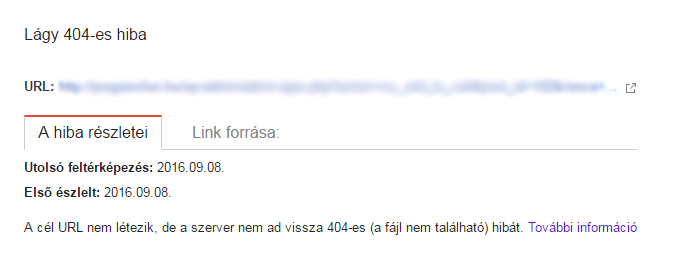
Che cosa significa?
Solo perché la vostra pagina 404 sembra una pagina 404, non significa che lo sia. La pagina 404 che un utente vede è un contenuto. Il messaggio visibile fa capire che la pagina non esiste più. Spesso i proprietari dei siti web inseriscono nella pagina 404 link utili o immagini divertenti.
Lo scopo di una pagina 404 è la risposta che viene visualizzata durante il crawling. Il codice di risposta HTTP per l'intestazione dovrebbe essere 404 (non trovato) o 410 (mancante).
Se la pagina di errore 404 viene restituita ed è elencata come un errore soft 404, significa che il codice di risposta non è 404.
Un'altra situazione in cui può verificarsi un errore 404 è quando un reindirizzamento 301 punta a pagine non correlate, come la pagina principale.
La posizione ufficiale di Google:
Per una pagina che non esiste (o che viene reindirizzata alla pagina principale), un codice diverso da 404 o 410 HTML può essere problematico.
Fornisce alcune linee guida, ma non è del tutto chiaro quando sia opportuno reindirizzare la pagina scaduta alla pagina principale e quando no. In pratica, se si reindirizzano molte pagine alla pagina principale, Google potrebbe interpretare gli URL reindirizzati come errori 404 morbidi anziché come veri e propri reindirizzamenti 301.
Pertanto, se la vecchia pagina viene reindirizzata a una pagina correlata, è improbabile che venga generato un errore 404 soft.
Perché è importante?
Se l'elenco degli errori soft 404 non contiene pagine critiche, la loro correzione non è immediata. Se le pagine critiche sono elencate come errori soft 404, è necessario intervenire rapidamente.
Come risolvere il problema?
Per i siti che sono non esistono più:
- Utilizzate un codice 404 o 410 se la pagina non esiste più e non riceve traffico o link significativi. Assicurarsi che il codice di risposta del server sia 404 o 410, non 200.
- I reindirizzamenti 301 sono utilizzati per reindirizzare le vecchie pagine a nuove pagine pertinenti.
- Non indirizzare un gran numero di pagine morte alla pagina principale.
Per i siti che sono persone che vivono e non dovrebbe dare un errore 404 soft:
- Assicuratevi di avere la giusta quantità di contenuti nella pagina, poiché un contenuto troppo scarso può sembrare un errore 404 non corretto.
- Assicuratevi che il contenuto della pagina non sembri una pagina 404.
La soft 404 è uno strano errore. Può causare molta confusione perché è un ibrido tra una pagina 404 e una pagina normale e quindi non può essere sempre chiaramente identificato. Il segreto è assicurarsi che le pagine più importanti non presentino errori soft 404.
B, Errore 404
Un 404 significa che Googlebot sta cercando di scansionare una pagina che non esiste. Mostra un errore 404 anche se un altro sito web o una sottopagina rimanda a una pagina inesistente.
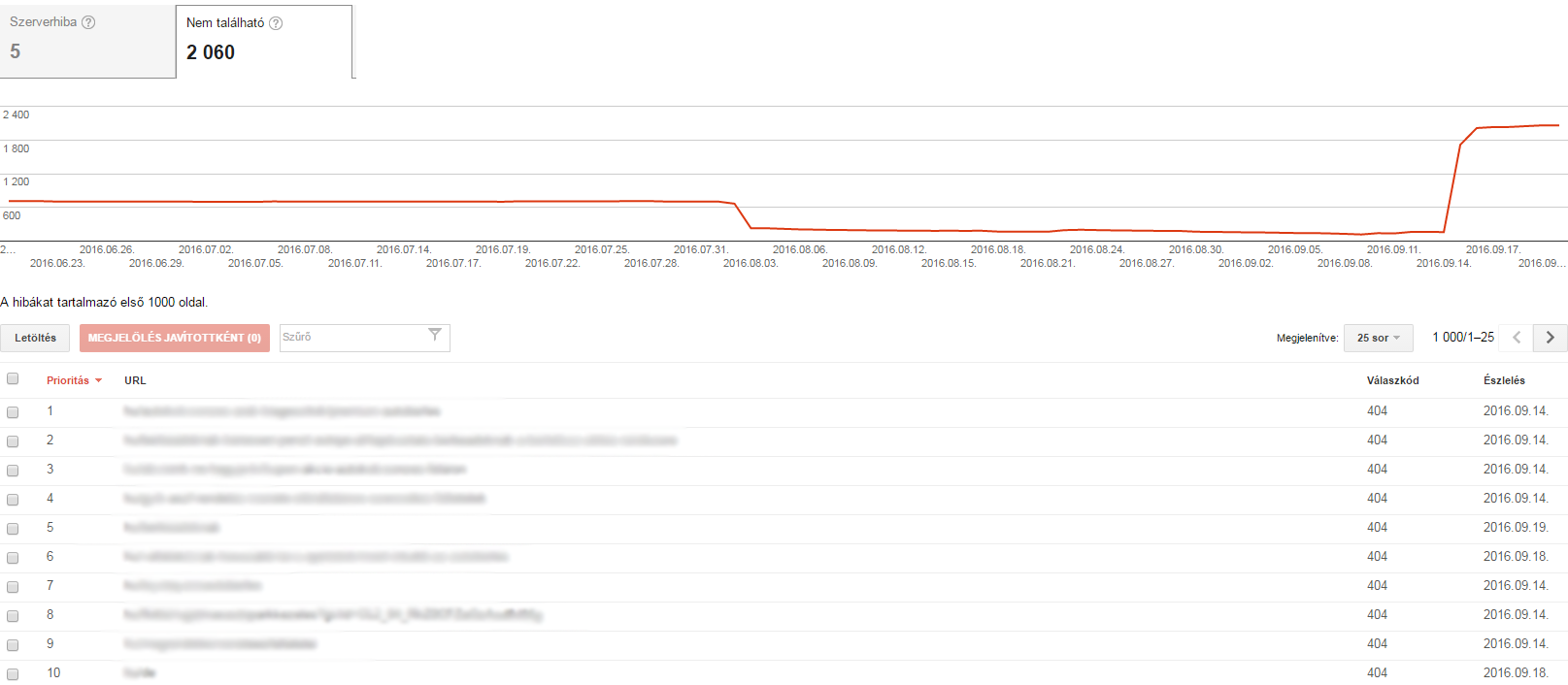
Che cosa significa?
La politica di Google dice:
In generale, gli errori 404 non hanno alcun effetto sulle classifiche di Google di un sito web, quindi si possono ignorare.
Questo va bene, ma se le pagine critiche danno errori 404, non possiamo ignorarle.
C'è una differenza tra ignorare il problema e rimanere in ufficio fino a notte fonda per risolverlo.
Un consiglio senza tempo:
Se si verifica un errore 404, a meno che non si tratti della pagina:
a, molti link importanti da fonti esterne
b, riceve una quantità significativa di traffico
c, ha un URL evidente a cui i visitatori possono accedere facilmente,
Lasciamolo come 404.
La parte più difficile del lavoro consiste nel decidere cosa conta come un link esterno importante e una quantità significativa di traffico per un determinato URL.
Perché è importante?
Questo è forse uno dei problemi più complicati e più semplici che possano sorgere. L'enorme numero di URL 404 sui siti di medie e grandi dimensioni è un deterrente sufficiente.
Richiedono una soluzione immediata quando le pagine importanti danno un codice di errore 404. Come ha detto Google, se la pagina è stata disattivata per molto tempo e non soddisfa i criteri di cui sopra, lasciatela così com'è. Per quanto sia doloroso vedere centinaia di errori negli Strumenti per i Webmaster, ignorateli.
Come risolvere il problema?
Se la vostra pagina importante mostra un errore 404 e non volete lasciarla così, fate come segue:
- Assicurarsi che la pagina sia pubblicata e non salvata come bozza.
- Assicuratevi che l'URL 404 sia la pagina corretta e non una variazione.
- Verificare se l'errore è visibile nella versione www o no www, http o https.
- Se non si vuole far rivivere la pagina, ma si vuole reindirizzarla altrove, assicurarsi di reindirizzarla alla pagina più pertinente.
In breve, se il vostro sito è morto, rendetelo di nuovo vivo. Se non volete renderlo vivo, fatelo diventare una buona pagina (301).
Come impedire che le vecchie pagine 404 appaiano nel report degli errori di crawling?
Se la pagina di errore 404 non serve più, Google consiglia di ignorarla. Tuttavia, per evitare che ricompaia nel rapporto Errori di crawling, si possono fare alcune cose.
Google mostra gli errori 404 in primo luogo se c'è un link all'interno della pagina o da un sito web esterno. In altre parole, se si digita un URL, questo non verrà visualizzato negli errori di crawl a meno che non si ottenga un link da qualche parte.
Per scoprire da dove proviene il collegamento alla pagina danneggiata, fare clic sull'URL. Quindi individuare il collegamento nel codice sorgente della pagina e correggerlo.
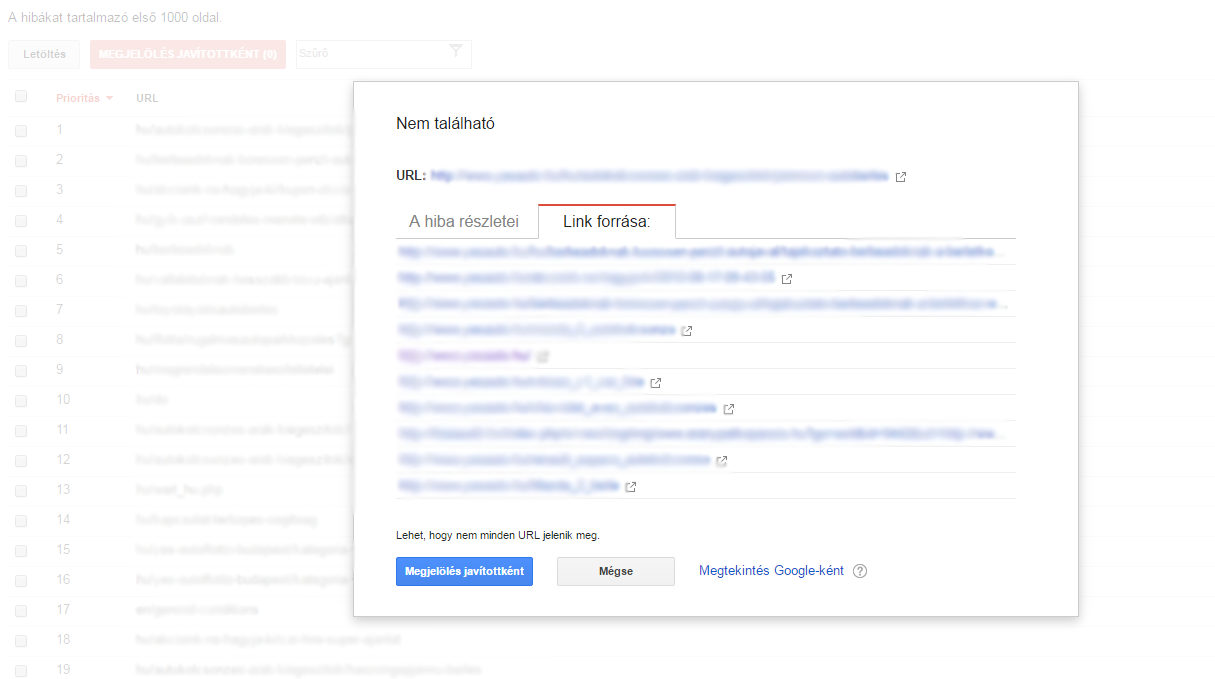
È un lavoro noioso, ma se si vuole evitare che la pagina 404 appaia nel rapporto, è necessario rimuovere il link interrotto da ogni pagina. Anche dai siti web esterni.
Se si riceve un link dalla vecchia mappa del sito, è necessario rimuoverlo anche da lì. Non reindirizzateli alla nuova sitemap.
C, Accesso negato
L'accesso negato significa che Googlebot non può effettuare il crawling della pagina.
Che cosa significa?
Gli errori di accesso negato spesso bloccano Googlebot nei seguenti casi:
- Dobbiamo chiedere agli utenti di accedere al sito per visualizzare l'URL perché Googlebot lo blocca.
- Il file robots.txt blocca Googlebot, compresi singoli URL, una cartella o addirittura l'intero sito web.
- Il provider di hosting blocca Googlebot o il server richiede un'autenticazione degli utenti basata su proxy.
Perché è importante?
Come nel caso degli errori soft 404 e 404, se è importante che una pagina bloccata venga strisciata e indicizzata, dobbiamo agire immediatamente.
Se non si vuole che la pagina venga strisciata e indicizzata, si può semplicemente ignorarla.
Come risolvere il problema?
Per risolvere gli errori di accesso negato, è necessario rimuovere gli elementi che bloccano l'accesso a Googlebot:
- Rimuovere il check-in dalle pagine che si desidera sottoporre a crawling da parte di Google, sia che si tratti di una pagina interna che di un pop-up.
- Controlliamo il file robots.txt, sappiamo che le pagine che vi si trovano significano che saranno bloccate.
- Utilizziamo il robots.txt checker per vedere se ci sono errori e per testare URL specifici.
- Utilizzate lo strumento Visualizza come Google per scoprire come il vostro sito appare a Google.
Anche se non è così comune come un errore 404, un errore di accesso negato può comunque danneggiare le classifiche del sito se vengono bloccate le pagine sbagliate.
D, Non seguito
Che cosa significa?
Da non confondere con l'attributo di link "nofollow", un errore not followed significa che Google non può seguire l'URL. La maggior parte di questi errori è causata da Flash, contenuti Javascript o reindirizzamenti.
Perché è importante?
Se si verifica un problema non seguito con un URL ad alta priorità, allora sì, è importante.
Se l'errore proviene da vecchi URL non più attivi o se alcuni dei loro parametri non sono indicizzati e sono solo un'opzione aggiuntiva, la priorità è bassa, ma devono comunque essere analizzati.
Come risolvere il problema?
Google e altri motori di ricerca hanno identificato diversi elementi che possono impedire il crawling: JavaScript, cookie, ID univoco, frame, DHTML, contenuti Flash.
Utilizziamo il Richiesta e visualizzazione per vedere cosa vede Google. Se noi, come Google, non riusciamo a vedere la pagina o ci sfugge un contenuto importante a causa di una delle tecnologie di cui sopra, c'è un bug. In fondo, senza contenuti e link visibili, l'URL non può essere tracciato.
Se c'è un problema di parametri, controlliamo come Google gestisce i nostri parametri.
Le pagine non seguite sono simili ai reindirizzamenti, si noti quanto segue:
- Controllare le catene di reindirizzamento.
- Se possibile, aggiornare la struttura della pagina in modo che tutte le sottopagine siano accessibili da una pagina statica.
- La mappa del sito non deve includere l'URL reindirizzato, tranne l'URL di destinazione.
E, errori del server e del DNS
Alla voce errori URL, Google elenca ancora una volta gli errori del server e del DNS, proprio come fa per gli errori del sito web.
La posizione di Google è che questi errori dovrebbero essere trattati alla stregua degli errori DNS e del server a livello di sito.
Se si dispone di un'impostazione separata per gli URL personalizzati, come i minisiti, o si utilizza una configurazione diversa per alcuni URL all'interno del proprio dominio, questi possono apparire qui.
Riepilogo degli errori di mappatura
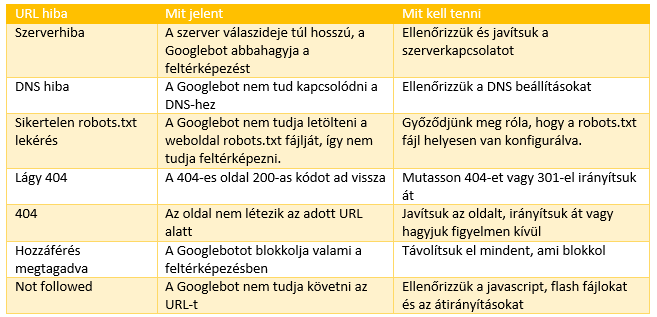
Conclusione
Nessuno vuole correggere uno per uno errori URL apparentemente insignificanti o, al contrario, farsi prendere dal panico quando vede migliaia di errori negli strumenti per i Webmaster.
Con l'esperienza e la ripetizione, possiamo imparare come reagire agli errori: quali sono importanti e quali possiamo tranquillamente ignorare.
La correzione degli errori non solo può contribuire a migliorare le classifiche di ricerca, ma può anche fornire una migliore esperienza utente ai visitatori e aiutarvi a raggiungere più velocemente i vostri obiettivi aziendali.
Fonte: moz.com