Comment corriger les erreurs de crawling dans les outils pour webmasters ? | Weboptim
Les outils pour les webmasters ont beaucoup évolué ces dernières années. Les sections Statistiques de recherche et Liens vers votre site sont les deux meilleures innovations à ce jour.
Section des erreurs de cartographie
Les outils pour webmasters peuvent être divisés en deux parties principales : les erreurs de site web et les erreurs d'URL.
La classification des erreurs dans ces deux groupes est très utile, car il existe une nette différence entre les erreurs au niveau du site web et celles au niveau des sous-pages.
- Les erreurs au niveau du site web sont plus graves, car elles peuvent compromettre la convivialité de l'ensemble du site.
- Les erreurs d'URL sont liées à une sous-page et sont donc des problèmes moins urgents.
La page d'accueil de WMT vous donne un aperçu rapide de notre site, avec 3 outils importants : Erreurs d'indexation, Statistiques de recherche, Plans du site.
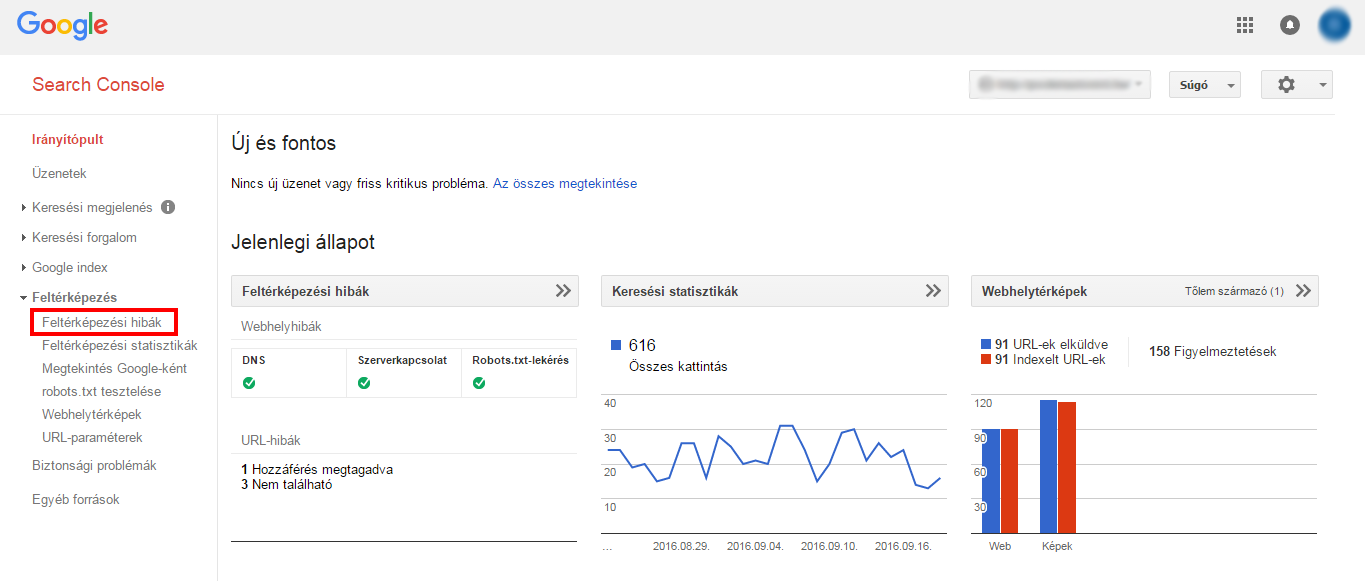
Les erreurs de cartographie sont facilement accessibles dans l'interface des Outils pour les webmasters.
1. les erreurs du site web
La section Erreurs du site web affiche les erreurs pour l'ensemble du site web. Il s'agit des erreurs de plus haut niveau, qui ne doivent jamais être ignorées. La page affiche les données des 90 derniers jours.
Si une activité a eu lieu au cours des 90 derniers jours, vous pouvez la consulter ici :
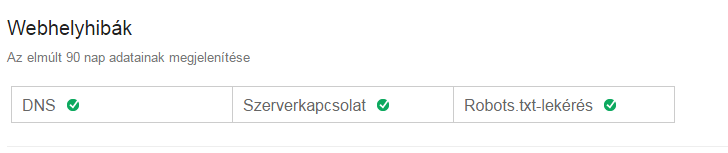
Si le site n'a pas connu d'erreur dans 100% au cours des 90 derniers jours, alors ceci :

À quelle fréquence vérifions-nous ces erreurs de site ?
Idéalement, nous devrions vérifier chaque jour s'il y a un problème. C'est un travail très monotone car, la plupart du temps, rien ne change, mais que se passe-t-il si nous ne vérifions pas et que nous manquons des erreurs critiques ?
Vérifiez l'absence d'erreurs antérieures au moins tous les 90 jours ! Cette section est critique et 100% sans erreur chaque jour est nécessaire.
A, erreurs d'ADN
Qu'est-ce que cela signifie ?
Les erreurs d'ADN sont importantes. La première et la plus importante des erreurs, car si Googlebot trouve une erreur DNS, cela signifie que Google ne peut pas se connecter au domaine via le serveur DNS.
Pourquoi est-ce important ?
Si un problème grave d'ADN est détecté, des mesures doivent être prises immédiatement. L'ADN est très important car c'est la première étape pour accéder au site. Nous devons prendre des mesures décisives si nous constatons une erreur DNS.
Comment y remédier ?
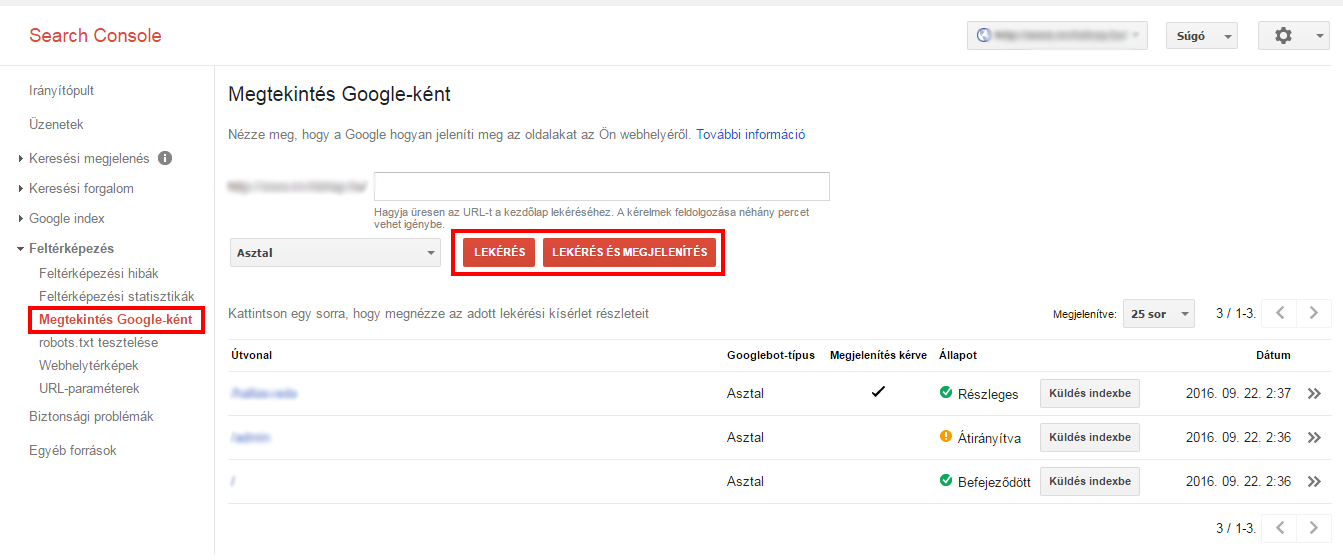
1) Tout d'abord, Google recommande une Voir comme Google où vous pouvez voir comment Googlebot cartographie votre site.
2) Si vous souhaitez uniquement vérifier l'état de l'ADN, utilisez le bouton Récupéré de sélectionner l'option. A Demande et affichage est un processus un peu plus lent, mais il est utile lorsque vous souhaitez comparer la façon dont Google considère votre page par rapport aux utilisateurs.
3. vérifiez votre fournisseur DNS. Si Google ne parvient pas à récupérer la page, d'autres mesures s'imposent.
4. vérifiez que le serveur affiche les codes d'erreur 404 et 500. Au lieu d'indiquer un échec de connexion, il doit afficher 404 (introuvable) ou 500 (erreur de serveur).
B, Erreurs du serveur
Qu'est-ce que cela signifie ?
Une erreur de serveur signifie généralement que le temps de réponse du serveur est trop long et que la demande a dépassé le temps autorisé. Lorsque Googlebot tente d'explorer la page, il n'attend qu'un certain temps de chargement avant de s'arrêter. Si le temps de chargement est trop long, il s'arrête.
Les erreurs de serveur sont différentes des erreurs DNS. Les erreurs DNS signifient que Googlebot ne peut pas voir l'URL en raison d'un problème DNS, tandis que les erreurs de serveur signifient que Google peut se connecter à la page mais ne peut pas la charger en raison d'une erreur de serveur.
Des erreurs de serveur peuvent se produire lorsque notre site reçoit trop de visiteurs et que le serveur ne peut pas gérer l'augmentation du trafic.
Pourquoi est-ce important ?
Tout comme les erreurs DNS, les erreurs de serveur sont également résolues rapidement. Il s'agit d'une erreur de base qui a un effet néfaste sur l'ensemble du site web.
Comment y remédier ?
Tout d'abord, assurez-vous que Googlebot peut se connecter à votre DNS.
Si le site web fonctionne correctement et que vous rencontrez cette erreur, cela peut signifier qu'il y a eu des erreurs de serveur dans le passé. Même si cette erreur a été résolue, nous devons apporter des modifications pour qu'elle ne se reproduise plus.
Guide officiel de Google pour la résolution des erreurs de serveur :
Utilisez l'outil View as Google pour voir comment Googlebot parcourt la page. Si nous interrogeons une page et que Google affiche la page principale sans aucun problème, nous pouvons supposer que Google est en mesure d'accéder à la page correctement.
Les erreurs de serveur peuvent avoir plusieurs causes/types : délai d'attente, en-têtes tronqués, rétablissement de la connexion, connexion refusée, échec de la connexion, délai d'attente de la connexion, absence de réponse. Pour corriger chaque erreur, utilisez l'aide des Outils pour les webmasters : https://support.google.com/webmasters/answer/35120?hl=en
C, Requête robots.txt infructueuse
Une demande de robots.txt infructueuse signifie que Googlebot ne peut pas récupérer le fichier robots.txt du site web, qui se trouve à l'URL [votredomaine.com]/robots.txt.
Qu'est-ce que cela signifie ?
L'une des choses les plus surprenantes à propos du fichier robots.txt est qu'il n'est nécessaire que si vous souhaitez que Google ne cartographie pas certaines pages (par exemple, les pages d'administration).
Pourquoi est-ce important ?
Cette question est très importante. Pour les petits sites web statiques avec peu de changements ou de nouvelles pages, elle n'est pas si importante. Mais il est évident que cela vaut la peine de l'améliorer.
Mais si votre site change fréquemment de contenu, il est urgent de résoudre le problème. Si Googlebot ne peut pas télécharger le fichier robots.txt, il ne peut pas explorer la page et les nouvelles pages ou les modifications ne seront pas indexées.
Comment y remédier ?
Assurez-vous que le fichier robots.txt est correctement configuré.
Vérifiez deux fois quelles sont les pages que vous ne voulez pas voir explorées.
Vérifier trois fois la ligne la plus importante „disallow:/”et assurez-vous qu'il n'existe pas, sauf si, pour une raison quelconque, vous ne souhaitez pas que le site web apparaisse dans les résultats de recherche.
Si le fichier semble correct, mais qu'il contient toujours des erreurs, utilisez le vérificateur de code HTML pour voir s'il renvoie des codes HTML de 200 ou 400.
Il est préférable de ne pas avoir de fichier robots.txt que d'en avoir un qui n'est pas correctement configuré. S'il n'y a pas de fichier robots.txt, Google explorera le site comme à l'accoutumée. S'il y en a un et qu'il est corrompu, il cessera d'explorer le site jusqu'à ce que le fichier soit corrigé.
2. les erreurs d'URL
Les erreurs d'URL sont très différentes des erreurs de site web, car elles n'affectent que des pages individuelles d'un site web, et non l'ensemble du site lui-même.
Webmaster Tools affiche les principales erreurs d'URL par catégorie - ordinateur de bureau, smartphone. Pour les grands sites, cette liste n'est probablement pas suffisante pour identifier toutes les erreurs, mais pour la plupart des sites, elle permet d'identifier tous les problèmes.
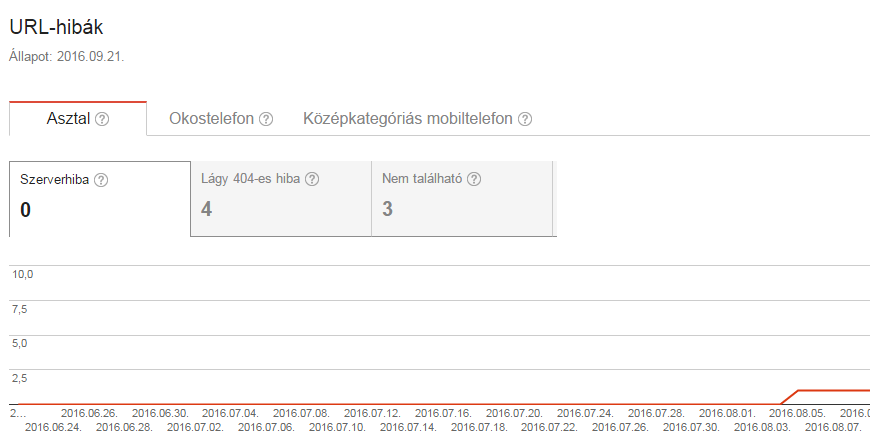
Nous voyons trop d'erreurs ? Marquez-les comme corrigées !
De nombreux propriétaires de sites web sont horrifiés par le nombre d'erreurs d'URL. La chose la plus importante à retenir est
- a, Google n'affiche que les erreurs les plus importantes
- b, certaines d'entre elles ont déjà été résolues
Si vous avez apporté des modifications radicales au site pour corriger des erreurs ou si vous pensez que de nombreuses erreurs d'URL n'existent plus, sélectionnez l'option Marquer comme corrigé et vérifiez à nouveau dans quelques jours.
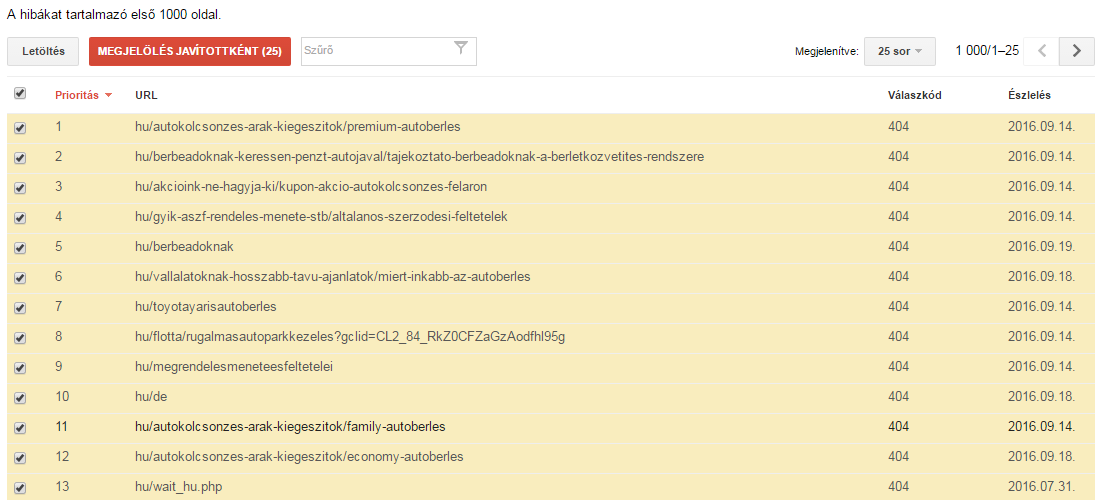
Si vous le faites, les erreurs disparaîtront du tableau et, si elles n'ont pas été corrigées, Google les affichera à nouveau lors de la prochaine exploration. Si nous avons effectivement corrigé les erreurs, elles ne réapparaîtront pas. Si les erreurs subsistent, nous saurons qu'elles affectent notre site.
A, doux 404
Une erreur 404 douce signifie que la sous-page renvoie des codes de réponse 200 (ok) au lieu de 404 (non trouvé).
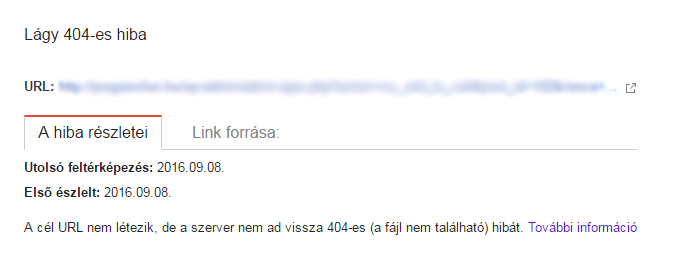
Qu'est-ce que cela signifie ?
Ce n'est pas parce que votre page 404 ressemble à une page 404 qu'elle en est une. La page 404 qu'un utilisateur voit est un élément de contenu. Le message visible lui indique que la page n'existe plus. Souvent, les propriétaires de sites web placent des liens utiles ou des images amusantes sur la page 404.
L'intérêt d'une page 404 est la réponse que vous voyez lors de l'exploration. Le code de réponse HTTP de l'en-tête doit être 404 (introuvable) ou 410 (manquant).
Si la page d'erreur 404 est renvoyée et qu'elle est répertoriée comme une erreur 404 douce, cela signifie que le code de réponse n'est pas 404.
Une autre situation dans laquelle une erreur 404 peut se produire est celle où une redirection 301 pointe vers des pages qui ne sont pas liées, comme la page principale.
Position officielle de Google :
Pour une page qui n'existe pas (ou qui est redirigée vers la page principale), un code autre que 404 ou 410 HTML peut être problématique.
Il donne quelques lignes directrices, mais il n'est pas tout à fait clair quand il est approprié de rediriger la page expirée vers la page principale et quand ce n'est pas le cas. En pratique, si vous redirigez de nombreuses pages vers la page principale, Google risque d'interpréter les URL redirigées comme des erreurs 404 légères plutôt que comme de véritables redirections 301.
Par conséquent, si l'ancienne page est redirigée vers une page connexe, il est peu probable qu'une erreur 404 soit soulevée.
Pourquoi est-ce important ?
Si la liste des erreurs "soft 404" ne contient pas de pages critiques, il n'est pas nécessaire de les corriger immédiatement. Si des pages critiques figurent dans la liste des erreurs 404 logicielles, il convient d'agir rapidement.
Comment y remédier ?
Pour les sites qui sont n'existent plus:
- Utilisez un code 404 ou 410 si la page n'existe plus et ne reçoit pas de trafic ou de liens significatifs. Assurez-vous que le code de réponse du serveur est 404 ou 410, et non 200.
- Les redirections 301 sont utilisées pour rediriger d'anciennes pages vers de nouvelles pages pertinentes.
- Ne pas diriger un grand nombre de pages mortes vers la page principale.
Pour les sites qui sont personnes vivant et ne doit pas produire d'erreur 404 :
- Veillez à ce que le contenu de la page soit suffisant, car un manque de contenu peut donner l'impression d'une erreur 404.
- Assurez-vous que le contenu de la page ne semble pas être une page 404.
Le "soft 404" est une erreur étrange. Elle peut être à l'origine d'une grande confusion car elle est un hybride entre une page 404 et une page normale et ne peut donc pas toujours être clairement identifiée. L'essentiel est de s'assurer que les pages les plus importantes ne sont pas des erreurs soft 404.
B, Erreur 404
Une erreur 404 signifie que Googlebot essaie d'explorer une page qui n'existe pas. Il affiche également une erreur 404 si un autre site web ou une sous-page renvoie à une page qui n'existe pas.
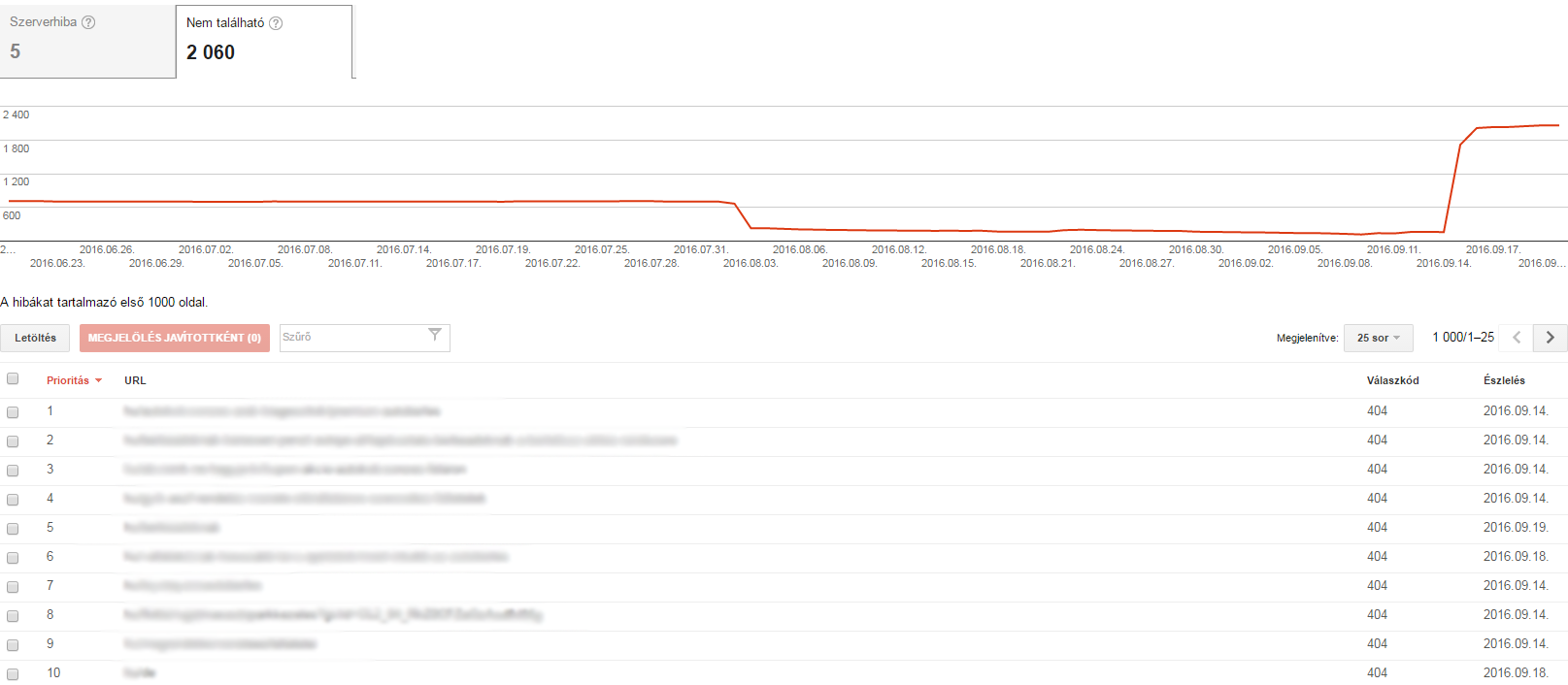
Qu'est-ce que cela signifie ?
Les règles de Google sont les suivantes :
En général, les erreurs 404 n'ont pas d'effet sur le classement Google d'un site web, vous pouvez donc les ignorer.
C'est une bonne chose, mais si des pages critiques génèrent des erreurs 404, nous ne pouvons pas les ignorer.
Il y a une différence entre ignorer le problème et rester au bureau jusque tard dans la nuit pour le résoudre.
Un conseil intemporel :
Si vous rencontrez une erreur 404, à moins que la page ne s'affiche :
a, de nombreux liens importants provenant de sources externes
b, reçoit un trafic important
c, a une URL évidente à laquelle les visiteurs peuvent facilement accéder,
Restons-en à 404.
La partie la plus difficile du travail consiste à déterminer ce qui constitue un lien externe important et un volume de trafic significatif pour une URL donnée.
Pourquoi est-ce important ?
C'est peut-être l'un des problèmes les plus délicats et les plus simples qui puissent se poser. Le nombre considérable d'URL 404 sur les sites de moyenne et grande taille est suffisamment dissuasif.
Ils ont besoin d'une solution immédiate lorsque des pages importantes affichent un code d'erreur 404. Comme l'a dit Google, si la page est en panne depuis longtemps et ne répond pas aux critères susmentionnés, laissez-la en l'état. Même s'il est pénible de voir des centaines d'erreurs dans les outils pour webmasters, il suffit de les ignorer.
Comment y remédier ?
Si votre page importante affiche une erreur 404 et que vous ne voulez pas la laisser dans cet état, procédez comme suit :
- Assurez-vous que la page est publiée et non enregistrée en tant que brouillon.
- Assurez-vous que l'URL 404 correspond à la page correcte et non à une variante.
- Vérifiez si l'erreur est visible dans la version www ou non www, http ou https.
- Si vous ne souhaitez pas faire revivre la page, mais la rediriger ailleurs, veillez à la rediriger vers la page la plus pertinente.
En bref, si votre site est mort, faites-le revivre. Si vous ne voulez pas le faire revivre, faites un 301 vers une bonne page.
Comment empêcher les anciennes pages 404 d'apparaître dans le rapport d'erreurs d'exploration ?
Si vous n'avez plus besoin de la page d'erreur 404, Google recommande de l'ignorer. Mais pour éviter qu'elle ne réapparaisse dans le rapport sur les erreurs d'exploration, il y a plusieurs choses que vous pouvez faire.
Google affiche les erreurs 404 en premier lieu s'il existe un lien à l'intérieur de la page ou à partir d'un site web externe. En d'autres termes, si vous tapez une URL, elle n'apparaîtra pas dans les erreurs de crawl à moins que vous n'obteniez un lien quelque part.
Pour savoir d'où vient le lien de la mauvaise page, cliquez sur l'URL. Trouvez ensuite le lien dans le code source de la page et corrigez-le.
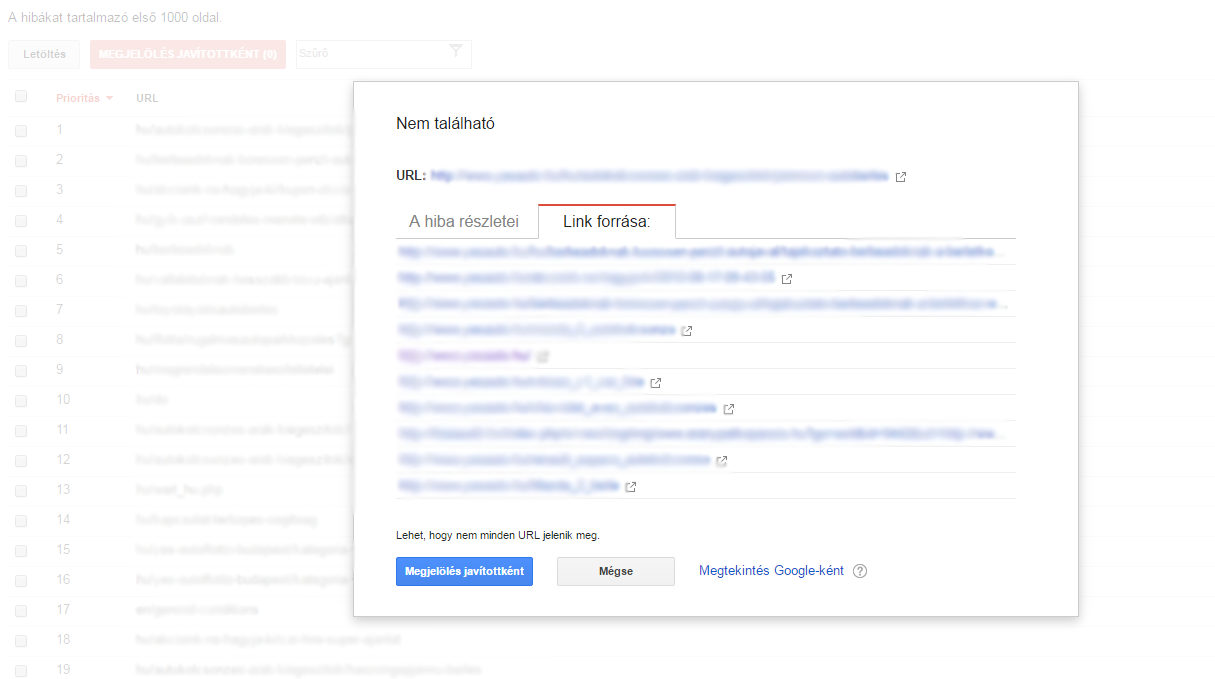
C'est un travail fastidieux, mais si vous voulez empêcher la page 404 d'apparaître dans le rapport, vous devez supprimer le lien brisé de chaque page. Même sur les sites web externes.
Si vous recevez un lien de l'ancien plan du site, vous devez également le supprimer. Ne les redirigez pas vers le nouveau plan du site.
C, Accès refusé
L'accès refusé signifie que Googlebot ne peut pas explorer la page.
Qu'est-ce que cela signifie ?
Les erreurs d'accès refusé bloquent souvent Googlebot dans les cas suivants :
- Nous devons demander aux utilisateurs de se connecter au site pour afficher l'URL car Googlebot la bloque.
- Le fichier robots.txt bloque Googlebot, y compris des URL individuelles, un dossier ou même l'ensemble du site web.
- Le fournisseur d'hébergement bloque Googlebot ou le serveur demande une authentification des utilisateurs basée sur un proxy.
Pourquoi est-ce important ?
Comme pour les soft 404 et les erreurs 404, s'il est important qu'une page bloquée soit explorée et indexée, nous devons agir immédiatement.
Si vous ne souhaitez pas que la page soit explorée et indexée, vous pouvez simplement l'ignorer.
Comment y remédier ?
Pour corriger les erreurs de refus d'accès, nous devons supprimer les éléments qui bloquent l'accès de Googlebot :
- Supprimez le check-in des pages que vous souhaitez que Google explore, qu'il s'agisse d'une page interne ou d'une fenêtre contextuelle.
- Nous vérifions le fichier robots.txt, nous savons que les pages qui s'y trouvent signifient qu'elles seront bloquées.
- Nous utilisons le vérificateur de robots.txt pour voir s'il contient des erreurs et pour tester des URL spécifiques.
- Utilisez l'outil View as Google pour savoir comment votre site apparaît à Google.
Bien qu'elle ne soit pas aussi courante qu'une erreur 404, une erreur d'accès refusé peut néanmoins nuire au classement de votre site si les mauvaises pages sont bloquées.
D, non suivi
Qu'est-ce que cela signifie ?
À ne pas confondre avec l'attribut de lien „nofollow”, une erreur "not followed" signifie que Google ne peut pas suivre l'URL. La plupart de ces erreurs sont causées par des contenus Flash, Javascript ou des redirections.
Pourquoi est-ce important ?
Si vous rencontrez un problème non suivi avec une URL de haute priorité, alors oui, c'est important.
Si l'erreur provient d'anciennes URL qui ne sont plus actives, ou si certains de leurs paramètres ne sont pas indexés et ne sont qu'une option supplémentaire, la priorité est faible, mais il convient tout de même de les analyser.
Comment y remédier ?
Google et d'autres moteurs de recherche ont identifié plusieurs éléments susceptibles d'empêcher l'exploration : JavaScript, cookies, ID unique, cadre, DHTML, contenu Flash.
Nous utilisons le Demande et affichage pour voir ce que Google voit. Si, en tant que Google, nous ne pouvons pas voir la page ou si un contenu important nous échappe en raison de l'une des technologies susmentionnées, c'est qu'il y a un bogue. En effet, sans contenu ni liens visibles, l'URL ne peut pas être suivie.
S'il y a un problème de paramètres, vérifions comment Google gère nos paramètres.
Les pages non suivies sont similaires à des redirections, mais elles présentent les caractéristiques suivantes :
- Vérifier les chaînes de redirection.
- Si possible, mettez à jour la structure des pages de manière à ce que toutes les sous-pages soient accessibles à partir d'une page statique.
- Le plan du site ne doit pas inclure l'URL redirigée, à l'exception de l'URL de destination.
E, Erreurs de serveur et de DNS
Sous la rubrique "Erreurs d'URL", Google répertorie à nouveau les erreurs de serveur et de DNS, comme il le fait pour les erreurs de site web.
La position de Google est que ces erreurs doivent être traitées de la même manière que les erreurs de DNS et de serveur au niveau du site.
Si vous disposez d'un paramètre distinct pour les URL personnalisées, telles que les mini-sites, ou si vous utilisez une configuration différente pour certaines URL au sein de votre domaine, elles peuvent apparaître ici.
Résumé des erreurs de cartographie
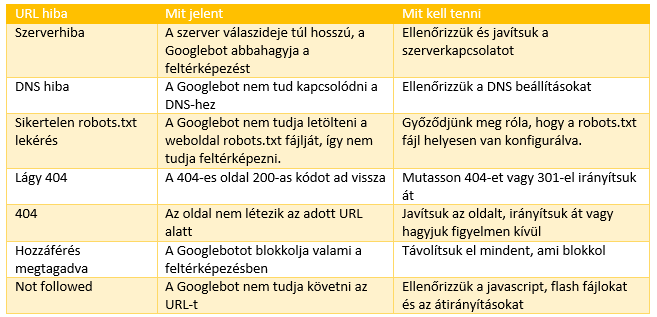
Conclusion
Personne ne souhaite passer en revue et corriger une à une des erreurs d'URL apparemment insignifiantes ou, au contraire, paniquer lorsqu'il voit des milliers d'erreurs dans les outils pour webmasters.
Avec l'expérience et la répétition, nous pouvons apprendre à réagir aux erreurs : celles qui sont importantes et celles que nous pouvons ignorer en toute sécurité.
La correction des erreurs peut non seulement contribuer à améliorer votre classement dans les moteurs de recherche, mais aussi offrir une meilleure expérience utilisateur aux visiteurs et vous aider à atteindre plus rapidement vos objectifs commerciaux.
Source : moz.com